Exploring Similarity: Triplets and How to Choose Them
June 15, 2022
Following our partner workshop in May, we started to re-assess our technical processes based on the feedback we received. Two take-away points from the workshop were:
When measuring similarity of metadata records, we should focus only on the metadata fields that concern subject and theme. This lead us to exclude some fields from our Sentence Embedding workflow (read about it in our earlier blogpost here), in particular those related to style, collection, and artist.
We should consider measuring similarity based exclusively on the curator-assigned subject tags, even if other free-text fields (specifically, title and description) exist. This lead us to experiment with an alternative machine learning technology referred to as Graph Embedding.
Another important outcome from our first experiments - which the workshop confirmed - was that the similarity scores we had computed did not work well when combining data from multiple museums. As the image below illustrates, each museum’s records remain fairly separated from each other. This may be because vocabularies and curating practices differ too much; or, simply, because the collections are inherently too different in terms of their content.
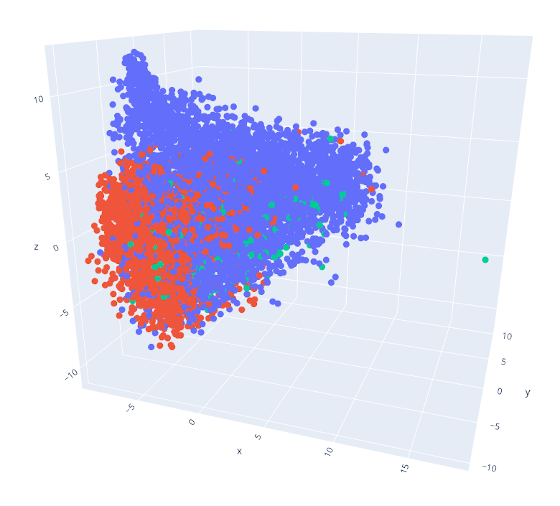
This outcome doesn’t exactly make our lives easier - after all, connecting collections is one of LiviaAI’s three main goals. But it isn’t entirely unexpected either. In fact, we had expected that metadata alone would be insufficent to connect across collections. Which is why we proposed this project in the first place!
The goal of LiviaAI is to teach computers how to recognize similar images, rather than similar metadata. To do this, we need to provide examples: the AI needs to see (lots of!) pairs of images that are similar to each other, but also images that are different, so that it learns what similarity looks like, without depending on the metadata.
Triplets
In AI terminology, a group of three images, where the first two are examples of similar images, and the third one is an example of a different image, is called a triplet. Good triplets will produce an AI model that can measure similarity in a useful way, allowing us to identify related images, no matter which collection they come from. To summarize our workflow:
- First, we compile lots of triplets, i.e. examples of images that are similar, and images that are different in terms of theme and subject.
- We feed the triplets into the AI, so it learns to “understand” what similarity looks like.
It is important to understand that the method we use to select our triplets is still based on the metadata: similar metadata means we’ll show it to the AI as an example of similar images; and because similar subject and themes are described in similar terms within one museum collection, this approach is sensible. But ultimately, the AI is supposed to learn the visual representation of similarity. And that, in turn, means it will have much less problems dealing with mixed content from different collections.
Comparing Approaches
So far, we’ve built triplets for two different museums (the Belvedere and the Wien Museum), and - as written above - using two different methods: Sentence Embeddings and Graph Embeddings. As a next step, we want to understand more about the real-world applicability of both approaches.
Each approach presents us with a quantitative measure of similarity that’s… technically… accurate: metadata records that include many identical terms, keywords and wording (perhaps with the odd synonym thrown in) will be reliably identified as similar. But the real world isn’t that simple, of course. Metadata isn’t always rich enough to provide enough material for the algorithm (or even humans!) to judge whether two images are similar enough in terms of subject and themes; and curation may not always be consistent, even within the same institution and collection.
That’s why we need your help: Below, you see a random triplet. Based on the metdata, our algorithm has selected images A and B as similar; and image C as different. Does the choice make sense? You can vote using the two buttons below.
Give us a thumbs-up if images A and B show similar motives or themes, and image C is different from A and B. Give us a thumbs-down if there is little similarity between A and B, or C is too similar to A or B.
Remember: what the computer thinks is a good triplet and what a person might think may be quite divergent, which is exactly why we need the human input (ie: your help). A human-made judgement on similarity and difference will always be valuable - whether the person making ith as professional art historical training or not.
We know that ratings are subjective. That’s no problem! We want to collect as much & as diverse feedback as possible. If people disagree, that will help us spot the difficult cases. It’s also worth bearing in mind that sometimes it is easier to judge what makes a bad triplet, than what makes a good one. Trust your instincts!
If you feel unsure about the process, we recommend:
- Don’t overthink it.
- Focus on image motives and themes, ignore the medium (e.g. painting, sculpture,…)
- Trust your instincts and rate according to your first impression.
- If a triplet looks confusing, this is likely due to ambiguous keywords. In this case, you can simply skip it.
After your vote, a new random triplet will load. Keep going as long as you want - the more data we collect, the better. If you need to skip a triplet, click the “Skip this Triplet” link. But please do this only in cases where you really (really!) cannot decide, or if there’s a problem loading a particular triplet. When in doubt, your gut feeling helps us more than no vote at all.
What Happens with the Data?
First of all: the data we collect is, of course, completely anonymous. All we record is your “Good” or “Bad” rating on each triplet. The data we collect will help us, most importantly, to understand whether there is any significant difference between triplets selected using Sentence Embeddings or Graph Embeddings. It will also help us get a better feel for which museum collection “works better”, as it were, with the two methods.
If we collect enough feedback (and that’s a big if!), we will also be able to train the AI only (or, at least, mainly) with triplets that have been confirmed by a human, which will significantly improve the quality of the model.
You can also access the rating app without the blog post here: https://rate-this-triplet.no5.at